Cet article constitue une version synthétique et simplifiée de notre étude scientifique complète. Pour une présentation détaillée de nos travaux, incluant toutes les expérimentations, analyses approfondies et résultats complets, nous vous mettrons notre article scientifique à disposition en accès libre dès sa publication.
Introduction à la génération augmentée de récupération (RAG)
La génération augmentée de récupération (Retrieval-Augmented Generation, ou RAG) est une technique avancée qui combine la puissance des modèles génératifs comme GPT [1], Llama [2], et d’autres, avec un système de recherche documentaire externe. Contrairement aux modèles traditionnels qui s’appuient uniquement sur leur mémoire interne, le RAG consulte généralement une base de connaissance documentaire pour produire des réponses précises, fiables et actualisées. Cela permet notamment de réduire le phénomène d’hallucination (informations inventées ou erronées), tout en assurant une meilleure traçabilité et la possibilité d’intégrer rapidement de nouvelles connaissances sans ré-entraîner le modèle.
Composition et fonctionnement des systèmes RAG
Un système RAG est constitué principalement de deux modules : un Retriever (module de récupération) et un Générateur. Le Retriever sélectionne les documents ou passages pertinents issus d’une base de connaissances externe en réponse à une requête utilisateur. Ce module exploite typiquement la recherche sémantique vectorielle, où questions et documents sont représentés sous forme de vecteurs afin d’évaluer leur proximité sémantique [3][4]. Les documents ainsi sélectionnés sont ensuite transmis au Générateur (un grand modèle de langage comme GPT ou Llama par exemple), qui produit une réponse finale enrichie et mieux documentée.
Avantages clés de RAG
Parmi les avantages majeurs du système RAG, on note principalement l’amélioration notable de la précision et de la fiabilité des réponses fournies par les modèles génératifs, grâce à la consultation directe de documents sources vérifiables. De plus, cette approche permet de séparer la gestion des connaissances du modèle lui-même, facilitant ainsi la mise à jour rapide des informations sans nécessité d’un nouvel entraînement coûteux. Enfin, la traçabilité accrue des informations améliore la confiance des utilisateurs dans les réponses fournies.
Limites du Retriever et l’importance du Reranker
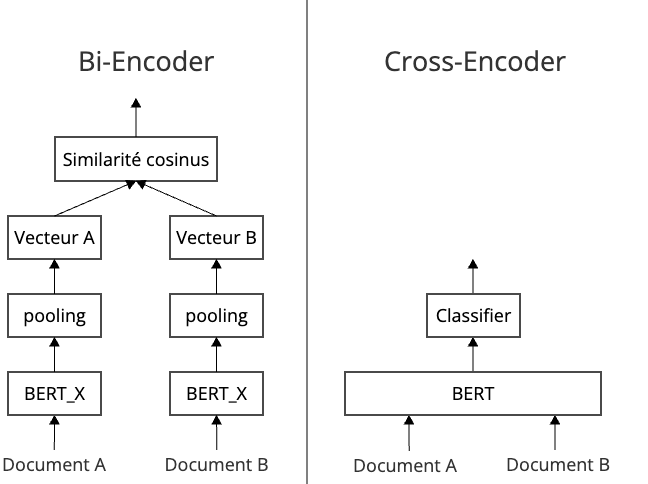
Dans les systèmes RAG, le Retriever s’appuie généralement sur une approche appelée bi-encoder [4], consistant à transformer séparément la requête de l’utilisateur et les documents en représentations vectorielles indépendantes, avant de mesurer leur proximité sémantique. Malgré son efficacité, cette méthode présente des limites : elle est sensible aux biais et peine souvent à capturer finement certaines nuances contextuelles, notamment lors de requêtes complexes ou ambiguës [5].
En pratique, pour compenser ces limites, le Retriever tend à sélectionner un grand nombre de documents candidats, ce qui entraîne une augmentation significative des ressources computationnelles nécessaires, mais aussi un risque de dégradation de la qualité des réponses finales. Pour résoudre ce problème, un troisième composant, appelé Reranker, est introduit pour affiner la sélection initiale et classer les documents par ordre de pertinence. Ce processus en deux étapes est illustré dans la figure 1 (« Système de récupération en deux étapes »).
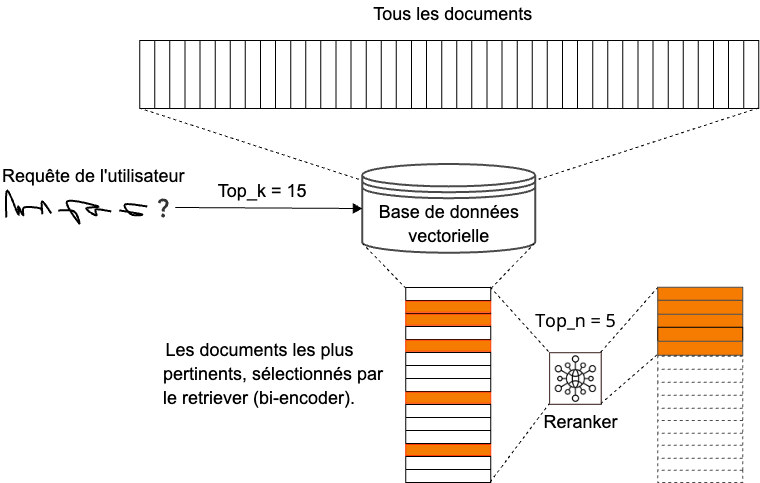
Parmi les techniques de reranking, deux grandes approches sont principalement utilisées. Le cross-encoder [7] encode simultanément la requête et le document, ce qui permet une analyse plus approfondie des interactions sémantiques entre les textes, mais entraîne un coût de calcul relativement élevé (voir figure « Structure de bi-encoder et de cross-encoder »).
Alternativement, le reranker génératif utilise des modèles génératifs comme GPT ou T5 [8] pour directement produire des scores de pertinence. Bien que flexible, cette méthode nécessite des ressources computationnelles considérables.
Dans notre étude, nous avons choisi de nous concentrer sur l’approche cross-encoder, largement adoptée pour son efficacité et sa précision. Notre objectif est de développer un reranker multilingue, léger, facile à déployer et entièrement open source. Nos expériences préliminaires, réalisées sur un ensemble de données en français, démontrent déjà la faisabilité et l’intérêt concret de cette approche.
Expérimentations et résultats
Pour entraîner et évaluer notre reranker, nous avons constitué un jeu de données spécifique combinant deux types de sources : d’une part, le STS Benchmark multilingue (STS-B) [9], spécialisé dans l’évaluation de la similarité sémantique entre paires de phrases ; d’autre part, plusieurs jeux de données en français dédiés aux questions-réponses (PIAF [10], FQuAD [11], SQuAD-French [12], et pandora-rag-fr [13]). Cette diversité permet à notre modèle d’apprendre à gérer différents styles linguistiques et thématiques, renforçant ainsi sa robustesse.
Lors de nos expérimentations de fine-tuning, nous avons testé différentes configurations en variant à la fois les modèles utilisés (principalement BERT [14] et DistilRoBERTa [15]) et la composition des jeux de données d’entraînement. Nous présentons deux configurations particulièrement réussies :
- La première configuration consiste à fine-tuner le modèle BERT de Google uniquement sur les données du STS Benchmark en français (stsb-fr).
- La seconde configuration utilise le modèle DistilRoBERTa-base, entraîné sur une combinaison étendue de données : STS Benchmark (stsb-fr) associé aux corpus de questions-réponses (PIAF, FQuAD, SQuAD-French, pandora-rag-fr).
Ces expérimentations visent à illustrer l’importance du choix des données utilisées lors du fine-tuning, ainsi que l’impact de leur diversité sur les performances globales du modèle.
Pour chaque expérience, les modèles ont été évalués sur plusieurs ensembles de données, à savoir :
1. Les ensembles de développement et de test du STS Benchmark en français (STS-B Dev et STS-B Test). Voir la Table 1.
| Expérience | STS-B Dev | STS-B Test | ||
| Pearson | Spearman | Pearson | Spearman | |
| BERT + stsb | 0.8722 | 0.8692 | 0.8362 | 0.8245 |
| DistilRoBERTa + stsb + qa dataset | 0.9219 | 0.9187 | 0.7565 | 0.7460 |
2. Trois jeux de données internes élaborés à partir de données prétraitées provenant de PIAF, FQuAD, SQuAD-French, pandora-rag-fr et stsb-fr :
- Un premier jeu intégrant l’ensemble des sources (PIAF, FQuAD, SQuAD-French, pandora-rag-fr et stsb-fr), évalué via la corrélation (Table 2).
- Un second jeu constitué de PIAF, FQuAD et SQuAD-French, évalué à l’aide d’indicateurs de classification binaire (Table 3).
- Un troisième jeu rassemblant PIAF, FQuAD, SQuAD-French et pandora-rag-fr, également évalué à l’aide d’indicateurs de classification binaire (Table 3).
| Expérience | Pearson | Spearman |
| BERT + stsb | 0.7741 | 0.7608 |
| DistilRoBERTa + stsb + qa dataset | 0.9522 | 0.8966 |
| Expérience | Dataset : PIAF, FQuAD et SQuAD-Fr | ||||
| Acc. | F1 | Prec. | Rec. | Avg. Prec. | |
| DistilRoBERTa + stsb + qa dataset | 0.9753 | 0.9754 | 0.9720 | 0.9788 | 0.9954 |
| BERT + stsb | 0.9527 | 0.9529 | 0.9603 | 0.9889 | |
| Expérience | Dataset : PIAF, FQuAD, SQuAD-Fr et pandora-rag-fr | ||||
| Acc. | F1 | Prec. | Rec. | Avg. Prec. | |
| DistilRoBERTa + stsb + qa dataset | 0.9767 | 0.9767 | 0.9791 | 0.9743 | 0.9952 |
| BERT + stsb | 0.9468 | 0.9472 | 0.9410 | 0.9534 | 0.9858 |
Tous nos processus de fine-tuning ont été réalisés sur une carte GPU T4 et reposent exclusivement sur l’ensemble d’entraînement. Il est toutefois important de souligner que, contrairement à ces processus, les étapes d’inférence et de benchmark, détaillées par la suite, ont été effectuées sur CPU.
Benchmarks du modèle Leviatan, du reranker Cohere, et du Reranker open source
Nous avons comparé nos modèles avec deux rerankers de référence : le modèle commercial (Cohere rerank-multilingual-v2.0 [16]) et un modèle open source (dangvantuan/CrossEncoder-camembert-large [17]).
L’évaluation a été réalisée en utilisant deux ensembles de test distincts, issus respectivement des jeux de données FQuAD et PIAF. Dans chaque cas, le système RAG utilise l’ensemble de test comme base documentaire.
Pour ces deux benchmarks, nous avons employé le modèle d’embedding intfloat/multilingual-e5-large de Microsoft [18] en tant que bi-encoder. Le premier filtrage, réalisé par ce bi-encoder, repose sur une mesure de similarité cosinus qui permet de sélectionner les 30 candidats les plus pertinents.
Le benchmark basé sur le jeu de données FQuAD Test comprend un total de 3 188 questions, tandis que celui reposant sur le jeu de données PIAF Test en inclut 1151.
Les performances ont été évaluées en mesurant le pourcentage d’exactitude selon la métrique Top-N [19], considérée pour trois niveaux de sélection : top 5, top 7 et top 10. Les résultats obtenus pour chacun des deux ensembles de test sont présentés dans la Table 4 et la Table 5.
| Modèle | Top 5 | Top 7 | Top 10 |
| Cohere Reranker | 92.50% | 93.48% | 94.26% |
| D.V. CrossEncoder | 52.23% | 62.33% | 71.46% |
| Leviatan Reranker #1 – DistilRoBERTa + stsb + qa dataset | 72.49% | 78.67% | 84.07% |
| Leviatan Reranker #2 – BERT + stsb | 84.54% | 87.92% | 90.90% |
| Modèle | Top 5 | Top 7 | Top 10 |
| Cohere Reranker | 95.57% | 96.35% | 97.22% |
| D.V. CrossEncoder | 61.77% | 69.24% | 78.63% |
| Leviatan Reranker #1 – DistilRoBERTa + stsb + qa dataset | 90.70% | 93.83% | 95.83% |
| Leviatan Reranker #2 – BERT + stsb | 94.87% | 96.00% | 96.96% |
Ce benchmark met en évidence la compétitivité des solutions commerciales par rapport aux approches open source et le modèle de Reranker Leviatan. Tandis que le reranker commercial Cohere offre des performances de très haut niveau, le modèle de Reranker Leviatan, démontre que des configurations optimisées peuvent se rapprocher de ces performances. Ces résultats ouvrent la voie à des travaux futurs visant à affiner davantage nos modèles, notamment en explorant des stratégies de fine-tuning plus robustes et en intégrant des jeux de données complémentaires.
Cependant, nous avons également identifié une limite liée à notre méthode de construction des exemples négatifs dans le dataset. En associant de façon aléatoire des questions à des contextes, nous avons involontairement créé des paires trop faciles à discriminer, ce qui limite la capacité du modèle à discerner finement les cas réellement complexes. Dans notre article complet, nous détaillons précisément la méthodologie utilisée pour construire le jeu de données, ainsi que l’analyse approfondie des erreurs observées.
À l’avenir, nous envisageons donc d’améliorer cette méthodologie en créant des exemples négatifs plus subtils, afin d’affiner encore davantage les performances de notre modèle de Reranker.
Ressources Open Source
Pour favoriser la transparence et encourager l’utilisation de nos travaux par la communauté, nous avons mis à disposition tous les scripts et modèles utilisés dans cette étude :
- Le script est accessible via notre dépôt GitHub : https://github.com/LeviatanAI/reranker-cross-encoder
- Les modèles entraînés et les jeux de données sont disponibles sur Hugging Face : https://huggingface.co/LeviatanAIResearch
- Papier scientifique : À venir.
Références
[1] OpenAI. Openai platform models. Accessed : 2025-02-21
[2] Meta. Llama 3.2 : Revolutionizing edge ai and vi- sion with open, customizable models, September 2024. Accessed : 2025-02-21.
[3] Vladimir Karpukhin, Barlas Oguz, Sewon Min, Le- dell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. CoRR, abs/2004.04906, 2020.
[4] Nils Reimers and Iryna Gurevych. Sentence-bert : Sen- tence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Me- thods in Natural Language Processing. Association for Computational Linguistics, 11 2019.
[5] Patrick S. H. Lewis, Ethan Perez, Aleksandra Pik- tus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge- intensive NLP tasks. CoRR, abs/2005.11401, 2020.
[6] James Briggs. Rerankers and two-stage retrieval. https://www.pinecone.io/learn/seri es/rag/rerankers/. In : Retrieval Augmented Generation,Accessed:2025-03-05.
[7] Rodrigo Nogueira and Kyunghyun Cho. Passage re- ranking with BERT. CoRR, abs/1901.04085, 2019.
[8] Kai Hui, Tao Chen, Zhen Qin, Honglei Zhuang, Fernando Diaz, Mike Bendersky, and Don Metzler. Re- trieval augmentation for t5 re-ranker using external sources, 2022.
[9] Daniel Cer, Mona Diab, Eneko Agirre, Iñigo LopezGazpio, and Lucia Specia. SemEval-2017 task 1 : Semantic textual similarity multilingual and crosslingual focused evaluation. In Steven Bethard, Marine Carpuat, Marianna Apidianaki, Saif M. Mohammad, Daniel Cer, and David Jurgens, editors, Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 1–14, Vancouver, Canada, August 2017. Association for Computational Linguis- tics.
[10] Rachel Keraron, Guillaume Lancrenon, Mathilde Bras, Frédéric Allary, Gilles Moyse, Thomas Scia- lom, Edmundo-Pavel Soriano-Morales, and Jacopo Staiano. Project piaf : Building a native french question-answering dataset, 2020.
[11] d’Hoffschmidt Martin, Vidal Maxime, Belblidia Wa- cim, and Brendlé Tom. FQuAD : French Ques-tion Answering Dataset. arXiv e-prints, arXiv:2002.06071, Feb 2020.
[12] Ali Kabbadj. French-squad : French machine reading for question answering. https://github.com /Alikabbadj/French-SQuAD, 2019. Accessed : 2025-03-05.
[13] pandora s. pandora-s / neural-bridge-rag-dataset- 12000-google-translated. https://huggingfac e.co/datasets/pandora-s/neural-bri dge-rag-dataset-12000-google-trans lated, 2024. Accessed : 2025-03-05.
[14] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kris- tina Toutanova. BERT : pre-training of deep bidirec- tional transformers for language understanding. CoRR, abs/1810.04805, 2018.
[15] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert : smaller, faster, cheaper and lighter. ArXiv, abs/1910.01108, 2019.
[16] Cohere. Improve search performance with a single line of code. https://cohere.com/rerank, 2025. Accessed : 2025-03-05.
[17] Van Tuan DANG. dangvantuan/crossencoder- camembert-large. https://huggingface.co /dangvantuan/CrossEncoder-camembert-large, 2022. Accessed : 2025-03-05.
[18] Liang Wang,Nan Yang,Xiaolong Huang,Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual e5 text embeddings : A technical report, 2024.
[19] Martin Riva. Top-n accuracy metrics. https://ww w.baeldung.com/cs/top-n-accuracy-m etrics, 2025. Accessed : 2025-03-05.